
How to implement file-based integration in Dynamics 365 FinOps using X++
December 17, 2020
Update 2025-02-04: The integration was updated to a new Azure Storage DLL A new way of working with Azure File Share from X++
There are many ways to implement integration with Dynamics 365 for Finance and Operations. One of the comprehensive descriptions of possible options can be found in this great post by Tayfun Sertan Yaman: How to integrate with Dynamics 365 for Finance and Operations.
The file-based approach is probably the oldest and commonly used integration type. Using this approach, an external system and D365FO send messages by reading/writing files into some shared network folder. It has the following advantages:
- Very clear responsibility (you either have a file in the correct folder or not);
- It is easy to troubleshoot (you can view the file, can modify it, etc..);
A good overview of some options how to work with files in D365FO can be found in the following video by Ludwig Reinhard Mass importing data in D365FO. He describes the pros and cons of two solutions:
Both these solutions are valid for a lot of cases, but they have the following issues:
- You need to install/support additional software(Cloud-based LogicApp or On-premise RIS)
- They use the Data Management Framework to load files, that doesn't support transactions. This can be critical for errors processing.
In this blog post, I try to describe another possible solution(with "Consuming external web services" type) for the File integration using X++ that is resolving these issues.
Solution description
Let's consider that we need to implement a periodic import of files and create ledger journals in D365FO based on these files. They have the following structure:
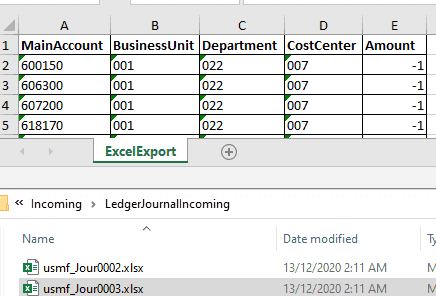
A company where ledger journals should be created is defined in a file name(text before "_") and one file represents one journal.
As the result we should get a posted journal in that company:
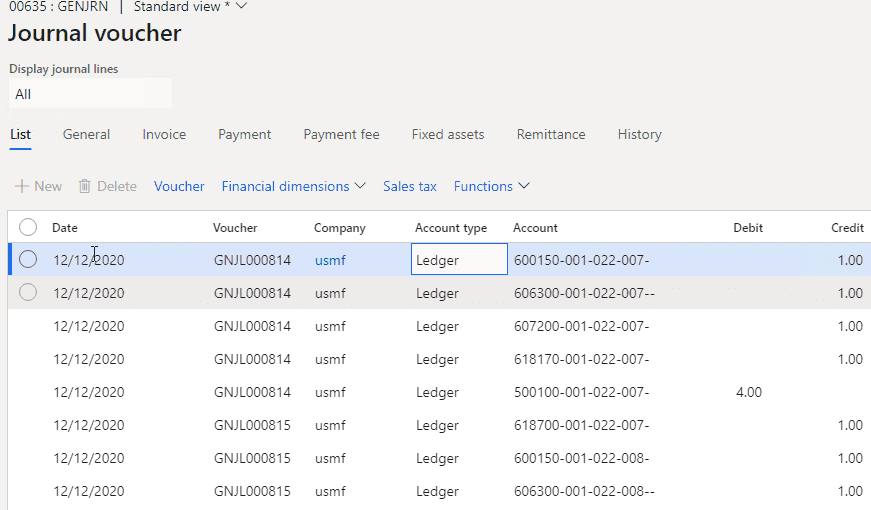
The integration will be based on two of my previous posts: How to read CSV/Excel files and How to create ledger journals in X++.
In order to copy files to Azure storage from the local PC the following command may be used
azcopy copy "C:\AAA\CCC\Files/*" "https://f365vmstorage.file.core.windows.net/ledgerinterface/TestUpload/SASToken"
(if used in bat file need to replace % to %% in SASToken value)Proposed solution
In the following section, I provide some code samples that can be used as a starting point to implement a periodic file import and processing.
File share connections form
As D365FO is a cloud-based system we need to put our files to some network location that is accessible from the cloud. Probably the simplest way to achieve this is to use Azure file share. It can be created with several clicks from Azure portal and you can even map it as a network drive in Windows(or use Azure Storage Explorer).
For this post I created a new account with the following folders:
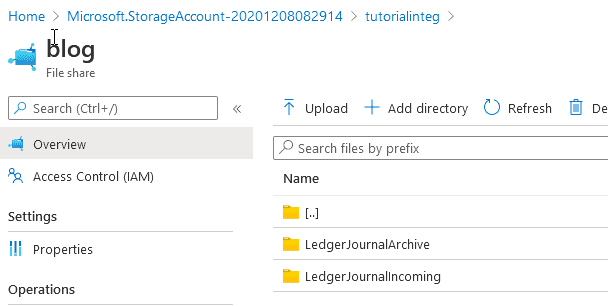
To store connection details I created a simple form in D365FO

Notes:
- Another alternative to Azure file storage can be an SFTP site. Check this article that describes this in details: Read File’s from SFTP Server and Write data in AX365. Update: (thanks to Tommy Skaue and Volker Deuss): SFTP connection doesn't recommended for new deployments: https://docs.microsoft.com/en-us/dynamics365/fin-ops-core/dev-itpro/deployment/known-issues-new-deployment-experience#ftp.
- Instead of storing Connection details in a D365FO table,a more secure solution is to create an Azure Key Vault and put all secrets into it(for example like this) and store a reference to this Key Vault in our new Connection table.
Inbound message types form
Next form to describe our integration will be Inbound message types form

This form contains 3 main sections:
1 - Details tab
-
Defines Incoming and Archive folders in our File share. There will be no Error folder: if an inbound file fails validation then the error details will be found in the message table.
-
Contains link to the Class that will do processing from this folder. The class should extend a base class DEVIntegProcessMessageBase and implement the following method:
abstract void processMessage(DEVIntegMessageTable _messageTable, DEVIntegMessageProcessResult _messageProcessResult)
{
...
}This method will be called by the integration engine outside of a transaction, so all transaction control can be implemented per Message type. There can be different options here: one transaction per message, multiple transactions(for example if a file contains several independent journals) or a single transaction per line. The result of processing and the current stage should be written to _messageProcessResult variable, so in case of an unhandled exception, this information can be saved for review. Also, this class will be created one time per full import session, so it can implement different caching options.
2 - Operation parameters tab
Contains parameters that are individual for the current operation. In our case it will be:
- Ledger journal name reference for journal creation
- Post the journal(No/Yes) and
- A file type(Excel or CSV)
3 - Advanced settings tab
Contains some common parameters: If we should use Parallel processing for our incoming files and how to move files to an Archive folder(with the same name or append DateTime to the file name). Parallel processing is based on this post: A simple way to implement a parallel batch processing in X++, so for example if we set it to 10 and have 1000 incoming messages, 10 batch threads with 100 messages each will be created.
Also, this form contains two servicing operations:
- Check connection button that tries to connect to the specified directory
- Import file button that can be used in testing scenarios to manually import a file from a user computer without connecting to network file share
Incoming messages form
This table will store the details on each inbound file.
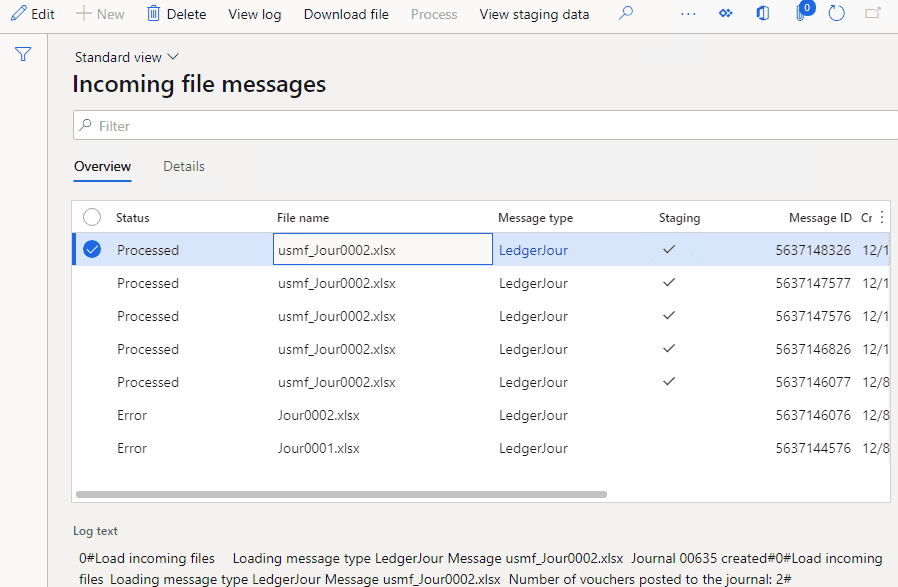
Every message has a status field that can contain the following values:
- Ready – a file was read to D365FO and successfully moved to the Archive folder.
- Hold – The user has decided not to process the file. This is an alternative to a delete option
- In process – system-generated status, a message is processing now
- Error – failed validation
- Processed – completed successfully
In this form it is also possible to do the following operations:
- View incoming file context
- Filter by different statuses
- View a detailed error message
- Change the status to process the message again
- View file processing statistics (processing duration, time, number of lines)
Load incoming file operation
It is a periodic batch job that we can run for one or multiple message types.
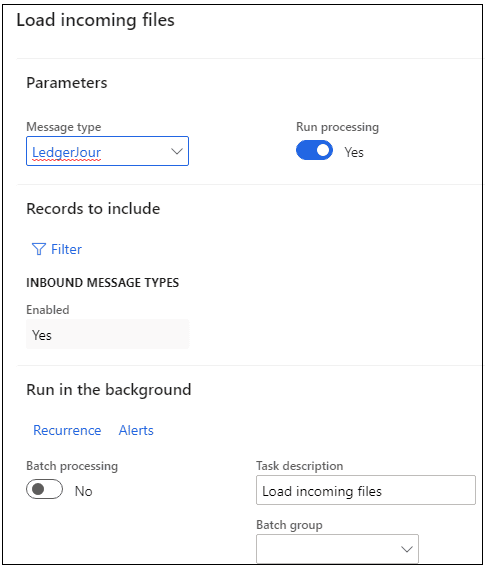
It connects to the shared folder, reads files, creates a record in Incoming messages table with Ready status, attaches a file content to this message and moves the file to an Archive directory. If Run processing is selected, after the load system will execute processing of the loaded messages.
Process incoming messages
Message processing may be executed as a separate operation - Process incoming messages that selects all not processed messages and calls the processing class for them.
The logic of how to process the file is different per message type/class. For the simple scenario, the class can just read the file content and create some data in one transaction. For this blog post, I implemented two step processing. See the sample diagram below:
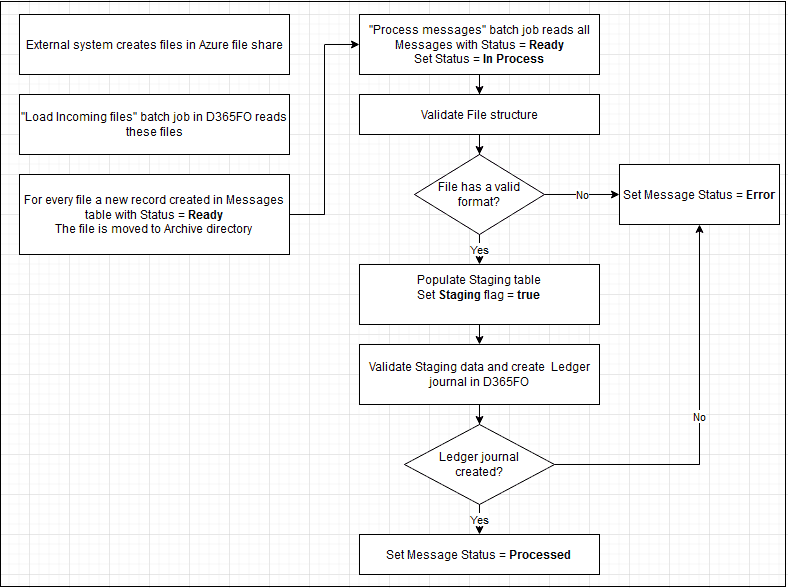
During the first step, the class reads the file and writes data into a staging table. A sample code for this:
while (fileReader.readNextRow())
{
linesStaging.clear();
lineNum++;
linesStaging.LineNumber = lineNum;
linesStaging.HeaderRefRecId = tutorialLedgerJourHeaderStaging.RecId;
linesStaging.MainAccount = fileReader.getStringByName('MainAccount');
linesStaging.BusinessUnit = fileReader.getStringByName('BusinessUnit');
linesStaging.Department = fileReader.getStringByName('Department');
linesStaging.CostCenter = fileReader.getStringByName('CostCenter');
linesStaging.Amount = fileReader.getRealByName('Amount');
DEV::validateWriteRecordCheck(tutorialLedgerJourLinesStaging);
tutorialLedgerJourLinesStaging.insert();
}Then based on this staging data values, a new journal is created. As I wrote in this post there are two options to create a ledger journal: either using LedgerJournalEngine class or using a data entity. The choice between these two should be made by answering the question: if the user wants to create the same journal manually, does he use manual entry or data import?. In this case, I want the result to be similar to manual entry, so LedgerJournalEngine class is used.
ledgerJournalTrans.AccountType = LedgerJournalACType::Ledger;
ledgerJournalTrans.modifiedField(fieldNum(LedgerJournalTrans, AccountType));
DimensionDefault dim;
dim = DEVDimensionHelper::setValueToDefaultDimensionCon(dim,
[DEVDimensionHelper::BusinessUnit(), tutorialLedgerJourLinesStaging.BusinessUnit,
DEVDimensionHelper::Department(), tutorialLedgerJourLinesStaging.Department,
DEVDimensionHelper::CostCenter(), tutorialLedgerJourLinesStaging.CostCenter ] );
ledgerJournalTrans.LedgerDimension = LedgerDimensionFacade::serviceCreateLedgerDimension(
LedgerDefaultAccountHelper::getDefaultAccountFromMainAccountId(tutorialLedgerJourLinesStaging.MainAccount), dim);
ledgerJournalTrans.modifiedField(fieldNum(LedgerJournalTrans, LedgerDimension));
ledgerJournalEngine.accountModified(LedgerJournalTrans);
....
ledgerJournalTrans.insert();After the journal creation, this class runs journal posting.
Error types and how to handle them
It is not a big task to create a journal based on a file. The complexity of integration is often related to exception processing and error monitoring. Let's discuss typical errors and how users can deal with them.
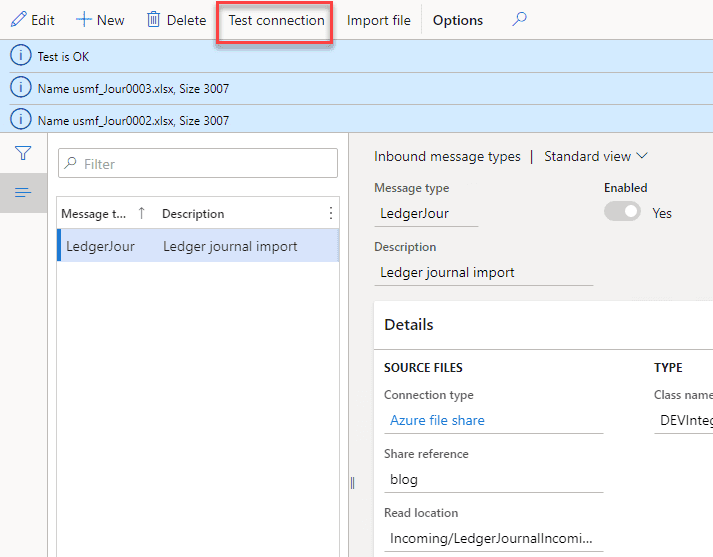
File share connection errors
If our batch job can't connect to a File share or read and move files, a batch job exception will be generated. It is a configuration error and it requires system administrator attention. Notification will be done using a batch job status. After troubleshooting the error system administrator can use the "Test connection" button to validate that the system can now connect to the file share.
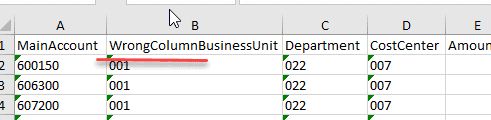
File format errors
The next error type is a wrong file format, so we can't even read the file content.
To test this case I renamed one of the columns
After the import users will see this file with the Error status. Notification can be done using standard filtering by the Status column.

Users can view the error log, then download the file and check the reason for this error. There may be two reasons:
- Our code that reads the file is wrong. In this case, we can send this file example to a developer to fix the logic. After fixing the problem we can run the Processing again.
- External system sent a file in the wrong format. In this case, the user can send this file back to the external party, then change the message status to Hold.
Data errors
The file has a correct structure but contains a wrong data(e.g.. values that don't exist)
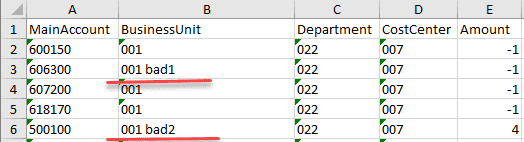
In this case, a Status of our Message will be Error and an Error log will be generated.
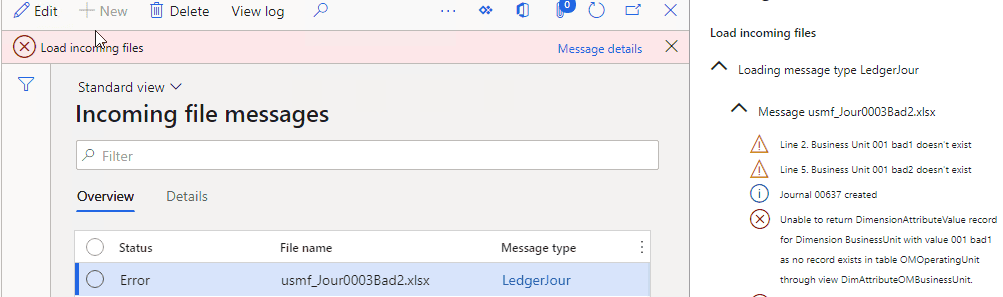
Users can view this error, display a Staging data to check the values from the File and take some actions(e.g. create missing values in the related tables if they are valid). After that, they can Process this message again.
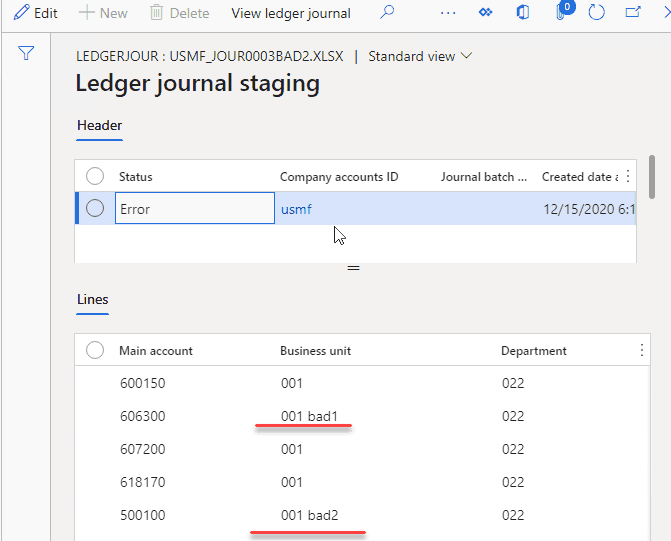
In some implementations(EDI), we can even allow staging data editing.
Posting errors
A similar type of error is a posting error. For example, in a current implementation if the journal is not balanced the error will be generated and the message gets the Error status:
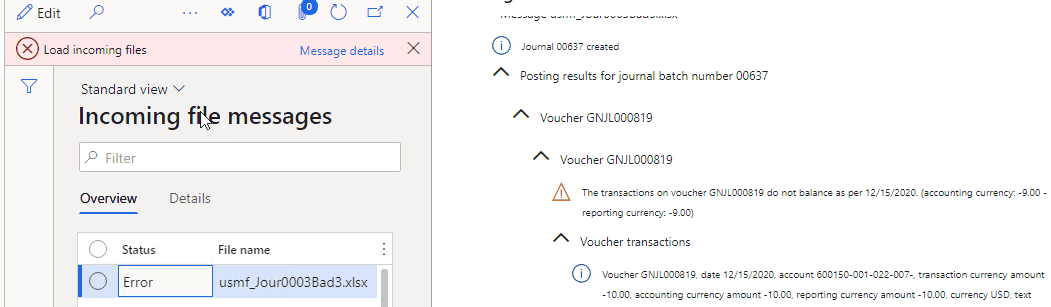
A possible variation to this approach is to create a document(journal in our case), try to post it, and even if posting fails, still set the message Status to Processed and leave the journal unposted, allowing accountants to decide what to do with it. As we don't process in transaction this will be a simple modification for our process class.
Wrong result errors
That is probably the worst scenario. The file was processed successfully, but the resulting journal contains some wrong transactions.
To analyse the result, users can view the staging data and check that they are correct
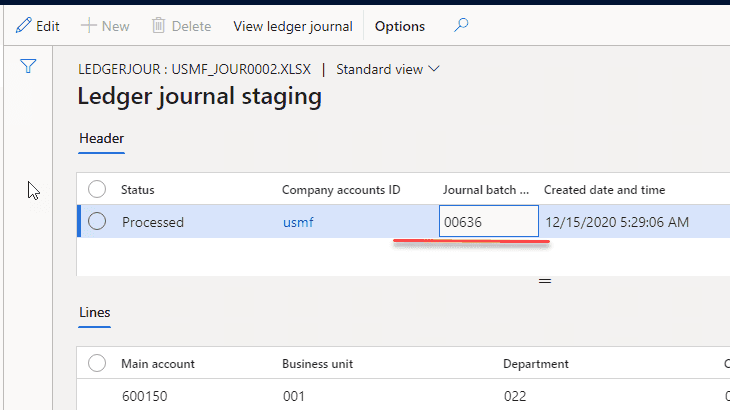
Another useful option to troubleshoot this scenario is a parameter in the Message types table for our operation: Post journal(No/Yes). We can switch it off, manually load a test file and check the created journal without posting it. And that may give an idea of what is wrong.
Summary
I provided a sample implementation for a File-based integration for D365FO. The main concept of it is to create a basic framework to simplify troubleshooting(most typical errors and all related data can be viewed in one form - Incoming messages) and provide some additional logging.
This may or may not be appropriate in your case(there are different options how to implement this). Anyway I recommend to use the following checklist while designing the integration: Integration solution specification
I uploaded files used for this post to the following folder
Another important question when you implement a solution like this: is how fast will be your integration. I wrote about sample steps for performance testing in the following post: D365FO Performance. Periodic import of one million ledger journal lines
I hope you find this information useful. As always, if you see any improvements, suggestions or have some questions about this work don't hesitate to contact me.
Tagged with:
Written by Denis Trunin
Similar posts:
- D365FO Integration: Import Purchase Orders from PDF using Gemini AI
- How to read Excel and CSV files in D365FO using X++
- Multicompany DMF integration in Dynamics 365 FinOps using X++
- D365FO Performance. Periodic import of one million ledger journal lines
- XppInteg - Azure Service Bus integration solution for Dynamics 365 FinOps
- How to create a new design for a Sales Invoice report in D365FO